RL-based Heuristics Learning for Model Checking
Introduction
Model checking is a formal verification technique that exhaustively explores the state space of a system to verify whether it satisfies a given property. However, in practical verification scenarios—such as debugging cycles where errors are fixed and re-verified, or regression testing after system modifications—running full verification from scratch each time is highly inefficient.
While directly reusing previously explored state spaces is challenging due to structural changes in the system, abstract knowledge about “which states are likely to lead to errors” can potentially be transferred across similar systems. Our research addresses this challenge by using reinforcement learning to automatically learn search heuristics based on predicate abstraction. This approach enables the learned heuristics to generalize across different system sizes and configurations, thereby accelerating repeated verification tasks.
In this work, we focus on falsification of safety properties, particularly deadlock detection in concurrent systems.
Approach
Predicate Abstraction for Feature Extraction
Predicate abstraction maps concrete states to fixed-dimensional Boolean vectors based on the satisfaction of predefined predicates. Given n predicates, each concrete state is abstracted to an n-dimensional Boolean vector:
\[\alpha(s) := \langle p_1(s), p_2(s), \ldots, p_n(s) \rangle\]This abstraction provides two key benefits:
- Meaningful features: Predicates are defined based on the property being verified, capturing relevant aspects of the system state.
- Fixed-dimensional representation: Regardless of system size, states are represented in the same n-dimensional space, enabling heuristic transfer across instances.
Heuristic Learning with Reinforcement Learning
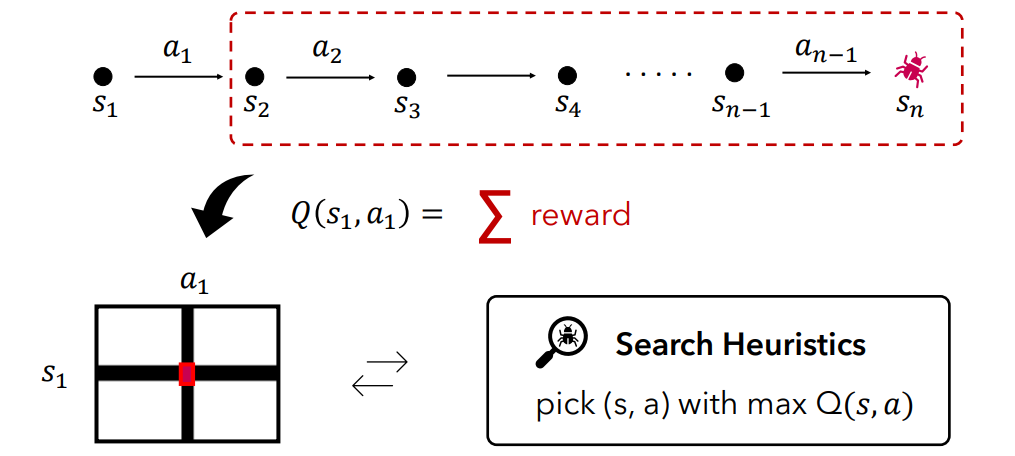
We train a Q-function Q(s, a) on the abstracted state space to estimate the likelihood of reaching an error state. The reward function assigns 1 for error states and 0 otherwise. The learned Q-values indicate how promising each state-action pair is for finding violations.
We employ two learning approaches:
- Q-table: Stores Q-values explicitly for each abstract state-action pair. Fast to train but limited to visited states.
- Deep Q-Network (DQN): Approximates the Q-function using a neural network, enabling generalization to unseen abstract states through pattern learning.
Heuristic-Guided Search
The learned Q-function is integrated into a best-first search framework. The state value function is defined as:
\[\hat{V}(s) = \max_a \hat{Q}(\alpha(s), a)\]States with higher V-values are prioritized during exploration, directing the search toward potential error states.
Experiments
Benchmark: Dining Philosophers
The Dining Philosophers problem is a classic concurrency benchmark where N philosophers sit around a circular table with forks between adjacent philosophers. Each philosopher cycles through states: think → hungry → wait → eat. The verification goal is to detect deadlock states where all philosophers hold one fork and wait indefinitely for the other.
Predicate Design
We define 13 predicates based on the system’s transition rules:
- 4 transition rules × 3 application targets (philosopher 0, philosopher 1, any other philosopher) = 12 predicates
- 1 predicate indicating whether the current state is a deadlock
This design ensures that instances of any size N are represented as 13-dimensional Boolean vectors.
Experimental Setup
| Parameter | Value |
|---|---|
| Training instance | N = 3 |
| Test instances | N = 4, 5, 6, 7, 8, 9, 10 |
| Training episodes | 500 |
| Number of predicates | 13 |
| Q-table hyperparameters | lr = 0.7, γ = 0.95 |
| DQN hyperparameters | lr = 0.02, γ = 0.95, hidden = 64 |
Baselines:
- BFS: Breadth-first search without heuristics
- Random: Best-first search with random priorities (average of 10 runs)
Results: Search Efficiency
Table. Number of states explored before finding deadlock.
| N | BFS | Random | Q-table | DQN |
|---|---|---|---|---|
| 4 | 341 | 185 | 70 | 58 |
| 5 | 1,457 | 701 | 132 | 79 |
| 6 | 6,189 | 2,713 | 316 | 152 |
| 7 | 26,333 | 9,498 | 884 | 308 |
| 8 | 112,309 | 30,244 | 2,765 | 519 |
| 9 | 479,765 | 61,448 | 7,174 | 892 |
| 10 | 1,853,449 | 93,459 | 16,783 | 1,939 |
Key findings (N=10):
- DQN explores 48× fewer states than Random
- DQN explores 956× fewer states than BFS
- Q-table explores 5.6× fewer states than Random
Results: Q-table Hit Ratio
| N | Hit Ratio |
|---|---|
| 4 | 38% |
| 7 | 4% |
| 10 | 0.2% |
The hit ratio—the proportion of encountered abstract states that were seen during training—drops dramatically as N increases. This explains Q-table’s limited generalization: unvisited abstract states have Q-value 0, providing no guidance.
DQN overcomes this limitation through neural network generalization, predicting reasonable Q-values for unseen states based on learned patterns.
Results: Search Time
Table. Time to find deadlock (milliseconds).
| N | BFS | Random | Q-table | DQN |
|---|---|---|---|---|
| 4 | 5 ms | 6 ms | 7 ms | 66 ms |
| 7 | 147 ms | 207 ms | 111 ms | 235 ms |
| 10 | 560,908 ms | 28,191 ms | 11,016 ms | 691 ms |
For small N, DQN is slower due to neural network inference overhead. However, for N ≥ 8, the reduction in explored states outweighs the inference cost. At N=10, DQN completes in under 1 second while Random requires ~28 seconds.
Publications
- H. Kang, B. Son, and K. Bae, RL-based Heuristic Learning for Model Checking. Korea Conference on Software Engineering (KCSE). 2026.
Contact
- Hyeyoon Kang hyoonk (at) postech.ac.kr
- Byoungho Son byhoson (at) postech.ac.kr
Last modified: 2026/02/25 (Hyeyoon Kang)